고정 헤더 영역
본문
맞춤법 오류 키워드를 활용한 SEO
검색 엔진 초기 시기에는 검색은 정말 간단했습니다. 검색 엔진의 알고리즘은 간단하게 ‘정확한 문구를 포함하는 색인된 모든 문서를 제공하고 키워드의 횟수에 따라 검색 결과 순서를 지정’으로 설명할 수 있을 정도였습니다.
이러한 환경에서 가장 효과적인 검색 엔진 최적화 전략 중의 하나는 철자가 틀린 키워드를 인위적으로 텍스트에 추가하여 타겟팅 하는 전략이었습니다. 검색 엔진은 메타 키워드 태그를 제공하여 페이지와 관련된 키워드 신호를 보낼 수 있도록 하겠고, 검색 엔진 최적화 전문가들은 이 점을 이용하여 철자가 틀린 키워드 타겟팅 전략을 활용하였습니다.
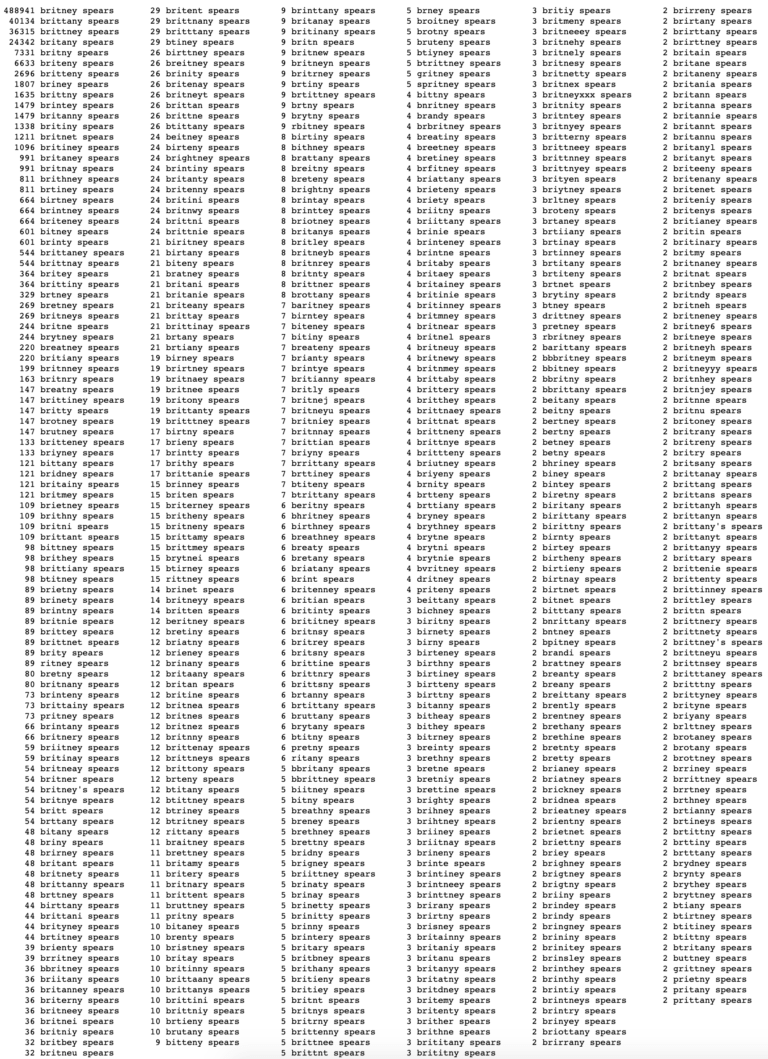
그렇다면 머신 러닝, AI 등 인공지능의 발달과 해당 기술이 깊숙하게 적용된 현재의 검색 엔진 환경에서 철자가 틀린 키워드 타겟팅 전략은 유효할까요? 결론부터 말씀드리자면, 더 이상은 아닙니다.
2013년 8월 업데이트된 구글의 허밍 버드 알고리즘은 이미 웹페이지의 컨텍스트 적 요소를 파악할 수 있게 되었습니다. 이후 랭크 브레인, 버트 알고리즘을 통해 웹페이지의 컨텍스트 적 의미를 추출하는 기술은 발전하였습니다.
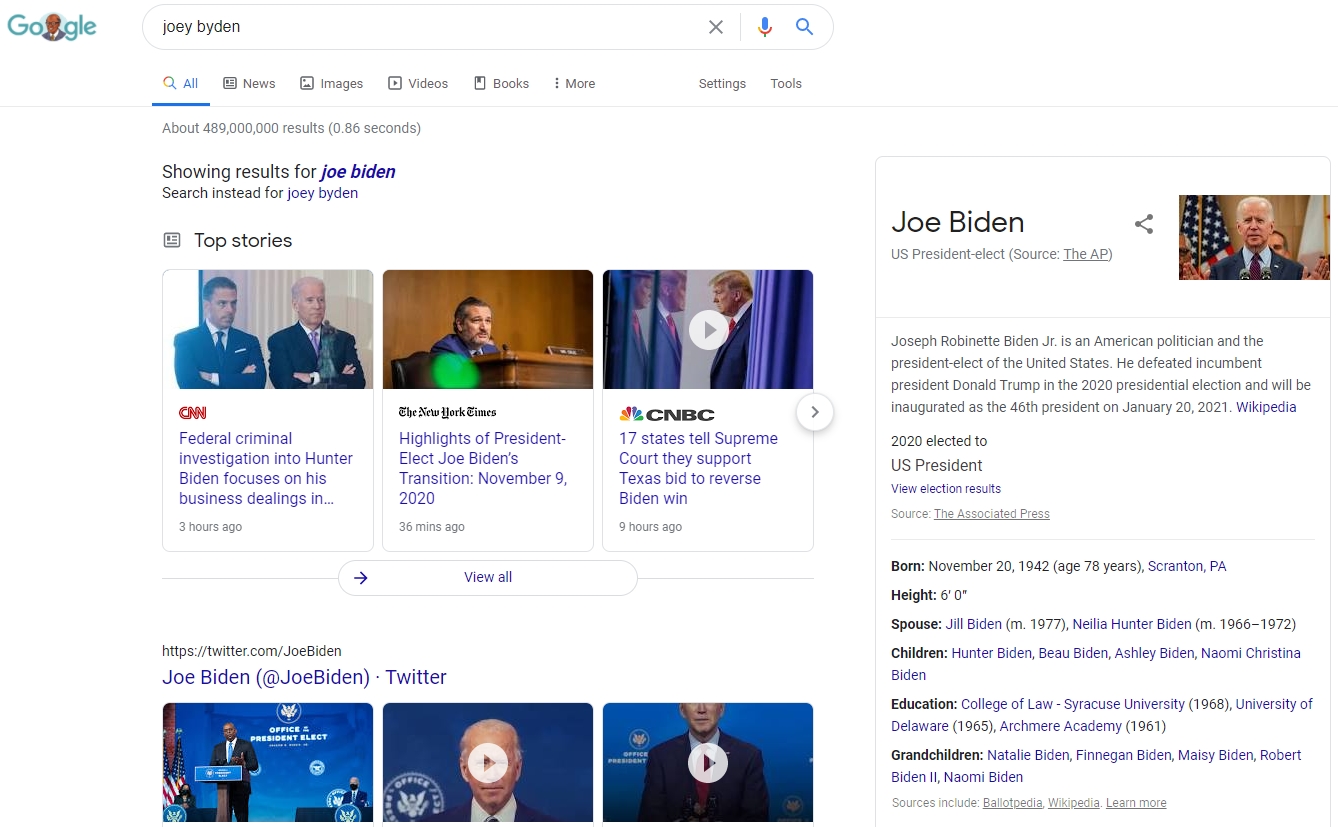
이러한 전략은 검색 알고리즘의 맹점을 이용한 전략이며 수많은 SEO 전문가들이 이 전략을 이용하였습니다. 그러나 정보 검색 및 NPL 분야의 엄청난 발전으로 인하여 더 이상 이 구글과 빙, 야후와 같은 검색 엔진은 메타 키워드 태그를 통해 키워드를 수집하지 않으며, 컨텍스트 적 해석을 통해 단어를 이해할 수 있게 되었습니다. 검색 엔진은 이미 검색 쿼리의 맞춤법 오류에 대한 인식하고 올바른 단어로 변환한 후 단어에 대한 결과를 보여줄 만큼 발전하였습니다.
어쩌면 아직도 SEO 전문가들 중에는 철자가 틀린 키워드 타겟팅 전략을 사용하고 있을 수 있습니다. 그러나 이 전략은 이미 검색 엔진 최적화를 저해하는 전략이 되었습니다. 구글과 빙이 고품질 웹사이트에 대한 리워드를 기획함에 따라 검색 엔진 최적화 관련 커뮤니티에서는 맞춤법이 맞지 않거나 철자가 맞지 않는 콘텐츠는 품질이 낮은 신호로 간주되어 실제로 사이트에 해를 끼칠 수 있다는 의견이 대부분입니다.
검색 엔진의 알고리즘은 진화하고 있습니다. 특히 AI 기술 발전에 힘입어 검색 광고를 포함해 검색 엔진 알고리즘은 더욱 정교하고 복잡해졌다고 보아야 합니다. 단순한 키워드 작업만으로 웹페이지의 검색 엔진 결과에 경쟁력을 확보하는 것은 이미 불가능합니다.
검색 엔진의 최종 목표는 검색자에게 검색 목적에 적합한 유용한 정보를 전달하는 것입니다. 검색 엔진 최적화의 올바른 방향은 독창적이고 풍부하며 유용한 컨텐츠를 제공하고 사용자가 정보를 소비하기 원활한 환경을 구성하는 것입니다.
반응형
'디지털 마케팅 > 검색엔진최적화' 카테고리의 다른 글
| 구글의 2020년 12월 코어 알고리즘 업데이트 분석 (0) | 2020.12.14 |
|---|---|
| 구글의 John Mueller : 블랙햇 금지! (0) | 2020.12.11 |
| 도메인 속 키워드 SEO에 효과적? (0) | 2020.12.10 |
| 워드프레스 보안 전략 (0) | 2020.12.08 |
| 구글 코어웹바이탈(핵심적인 웹 지표) 내년(2021년) 5월 검색결과에 적용 (0) | 2020.12.08 |




댓글 영역